Stock Analysis - Explaining the Model
This first article will explain my stock model, what stocks I analyzed, and the results. I’ll also go into my assumptions, what parts are subjective, and where I can improve. At a high level, my workflow is that I picked 15 stocks that had a good return in the past year, and narrowed that down to 11 which I would create a stock simulation. I would then record stock metrics of the simulations and other metrics listed on Yahoo Finance, create a multi-criteria decision analysis of the stocks, and buy the best-performing ones.
Here are the top ten if we want to cut to the chase:
NVDA
MSFT
AMZN
GOOG
AAPL
BAC
META
AMD
GRMN
TSM
I didn’t document the four stocks I excluded from simulating, so we’ll jump right into the 11 stocks I did simulate. In no particular order, the stocks were for Apple, Amazon, Cisco, Meta, Google, AMD, Nvidia, Microsoft, TSM, Bank of America, and Garmin. The simulation approach that I use is a Geometric Brownian Motion (GBM) model for the stock itself, and a Monte Carlo Simulation to run the GBM model 10,000 times. First, I go to Yahoo Finance and download the past year of stock data for a given stock I want to simulate. I then plot the stock data with Python and derive two key parameters, drift and volatility. Drift is the average amount the stock will change from day to day, and volatility is the variance in the amount that the stock will change from day to day.
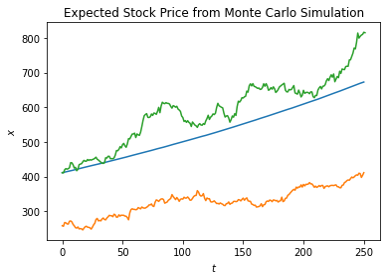
Once I derive the GBM parameters of a given stock, I run 10,000 simulations to derive a histogram of the simulated stock performances one year in the future and the average stock performance curve for the next year. The histogram notes the purchase price, expected price, 2% return price, 5% return price, and 10% return price. The Python program also returns the probability of profit as well as the probability of a 2%, 5%, and 10% return. The following graphs are for Microsoft (MSFT). In the first graph, the orange curve is the historical stock price for the past year by trading day, the green curve is a random sample of the simulated stock (meant to be a continuation of the historical price curve), and the blue curve is the expected path of the stock in the next year. The expected path is derived by taking the average of the 10,000 simulated stock curves. The histogram is the simulated stock prices at the end of the next year overlayed with expected price, purchase price, 2%, 5%, and 10% return price. Lastly, I appended all 10,000 simulated stock paths onto the historical stock price (the title says 500 paths, actually 10,000). This way we can see the spread in possible stock prices over time.


After simulating the stocks, I take the drift, volatility, and probability of profit parameters for the multi-criteria decision analysis (MCDA). I then go to Yahoo Finance and record the projected short-term, mid-term, and long-term stock performance. Yahoo Finance lists these as “up”, “down”, or “neutral”. I also record the recommendation rating, a number one through five, one being a strong buy and five being a sell. I then post-process the data to prep it for the MCDA including normalizing, scaling and shifting, and encoding parameters. I rank the parameters in order of importance and assign weights to them. A stock score is calculated and normalized from 0 to 100. With the scores, labeled as “Weights” in the last figure below, I allocate funds to a given stock. For example, NVDA scored a “100”. I then calculate ((weight)x(funds))/(sum of weights). Then buy that amount of stock rounded to the nearest round number. In the case of this analysis, I rounded up on my higher-ranking stocks and didn’t have any funds left to invest in my lower-ranked stocks.




An assumption that I make is that past stock performance is an indicator of future stock performance. I believe it is an indicator but certainly, other factors can affect a stock price. A subjective part of this model is when I assign ranks to the different features or parameters, I do so on my judgment and this can vary with one’s priorities or investing strategies. I’d like to improve this model by adding more parameters, changing parameters, and changing the post-processing strategy. I would also like to add more stocks, varied market stocks, and a machine-learning model in the long run.
Thanks for taking the time to read this! Feel free to reach out if you have questions or comments or want to take a closer look at the models! I plan to reanalyze these stocks to see how they performed in a few months and compare them with my simulated results, so stay tuned!